HackedGPT: Novas vulnerabilidades de IA abrem caminho para vazamento de dados privados
A Tenable Research descobriu sete vulnerabilidades e técnicas de ataque no ChatGPT, incluindo injeções indiretas exclusivas de prompts, exfiltração de informações pessoais do usuário, persistência, evasão e bypass de mecanismos de segurança.
Principais conclusões:
- A Tenable Research descobriu diversas vulnerabilidades novas e persistentes no ChatGPT da OpenAI que poderiam permitir que um invasor extraísse informações privadas das memórias e do histórico de bate-papo dos usuários.
- Essas vulnerabilidades, presentes no modelo mais recente do GPT-5, podem permitir que invasores explorem usuários sem o seu conhecimento por meio de diversos casos de uso prováveis, incluindo simplesmente fazer uma pergunta ao ChatGPT.
- As descobertas incluem uma vulnerabilidade que permite contornar os recursos de segurança do ChatGPT, criados para proteger os usuários contra esses ataques, e que pode levar ao roubo de dados privados dos usuários do ChatGPT.
- Centenas de milhões de usuários interagem com plataformas de aprendizagem online diariamente e podem ser vulneráveis a esses ataques.
Arquitetura
Injeções de prompts são uma vulnerabilidade na forma como os grandes modelos de linguagem (LLMs) processam dados de entrada. Um atacante pode manipular o LLM injetando instruções em quaisquer dados que ele receba, o que pode fazer com que o LLM ignore as instruções originais e execute ações não intencionais ou maliciosas. Especificamente, a injeção indireta de prompts ocorre quando um LLM encontra instruções inesperadas em uma fonte externa, como um documento ou site, em vez de um prompt direto do usuário. Como a injeção de prompts é um problema conhecido em LLMs, muitos fornecedores de IA criam salvaguardas para ajudar a mitigar e proteger contra ela. No entanto, descobrimos diversas vulnerabilidades e técnicas que aumentam significativamente o impacto potencial de ataques de injeção indireta de prompts. Para melhor compreender as descobertas, abordaremos primeiro alguns detalhes técnicos sobre o funcionamento do ChatGPT. (Para ir diretamente às descobertas, clique aqui .)
Mensagem do sistema
Cada modelo ChatGPT possui um conjunto de instruções criado pela OpenAI que descreve as capacidades e o contexto do modelo antes da conversa com o usuário. Isso é chamado de Prompt do Sistema. Pesquisadores frequentemente utilizam técnicas para extrair o Prompt do Sistema do ChatGPT (como pode ser visto aqui ), fornecendo informações sobre como o modelo de linguagem funciona. Ao analisar o Prompt do Sistema, podemos observar que o ChatGPT tem a capacidade de reter informações entre conversas usando a ferramenta bio , ou, como os usuários do ChatGPT podem conhecer, memórias . O contexto das memórias do usuário é anexado ao Prompt do Sistema, dando ao modelo acesso a qualquer informação (potencialmente privada) considerada importante em conversas anteriores. Além disso, podemos ver que o ChatGPT tem acesso a uma ferramenta web , permitindo que ele acesse informações atualizadas da internet com base em dois comandos: search e open_url .
A ferramenta biométrica , também conhecida como memórias.
O recurso de memória do ChatGPT mencionado acima está ativado por padrão. Se o usuário solicitar que o sistema se lembre de algo, ou se houver alguma informação que o mecanismo considere importante mesmo sem uma solicitação explícita, ela poderá ser armazenada por meio de memórias. Como pode ser visto no Prompt do Sistema, as memórias são invocadas internamente usando a ferramenta bio e enviadas como um contexto estático juntamente com ela. É importante observar que as memórias podem conter informações privadas sobre o usuário. As memórias são compartilhadas entre conversas e consideradas pelo LLM antes de cada resposta. Também é possível ter uma memória sobre o tipo de resposta desejada, que será levada em consideração sempre que o ChatGPT responder.
Além da sua memória de longo prazo, o ChatGPT considera a conversa e o contexto atuais ao responder. Ele pode consultar solicitações e mensagens anteriores ou seguir uma linha de raciocínio. Para evitar confusão, nos referiremos a esse tipo de memória como Contexto Conversacional.
A ferramenta da web
Durante nossa pesquisa sobre o ChatGPT, descobrimos algumas informações sobre o funcionamento da ferramenta web . Se o ChatGPT recebe uma URL diretamente do usuário ou decide que precisa visitar uma URL específica, ele o faz utilizando a funcionalidade `open_url` da ferramenta , que chamaremos de Contexto de Navegação. Ao fazer isso, ele geralmente utiliza o agente de usuário `ChatGPT-User` . Rapidamente percebemos que existe algum tipo de mecanismo de cache para essa navegação, já que, ao consultarmos uma URL que já estava aberta, o ChatGPT respondia sem navegar novamente.
Com base em nossos experimentos, o ChatGPT é extremamente suscetível à injeção de prompts durante a navegação, mas concluímos que o `open_url`, na verdade, delega a responsabilidade da navegação a um LLM alternativo chamado SearchGPT, que possui significativamente menos recursos e compreensão do contexto do usuário. Às vezes, o ChatGPT responde com os resultados da navegação do SearchGPT tal como estão, e outras vezes, ele recebe a saída completa e modifica sua resposta com base na pergunta. Como método de isolamento, o SearchGPT não tem acesso às memórias ou ao contexto do usuário. Portanto, apesar de ser suscetível à injeção de prompts no contexto de navegação, o usuário deve, teoricamente, estar seguro, já que o SearchGPT está realizando a navegação.


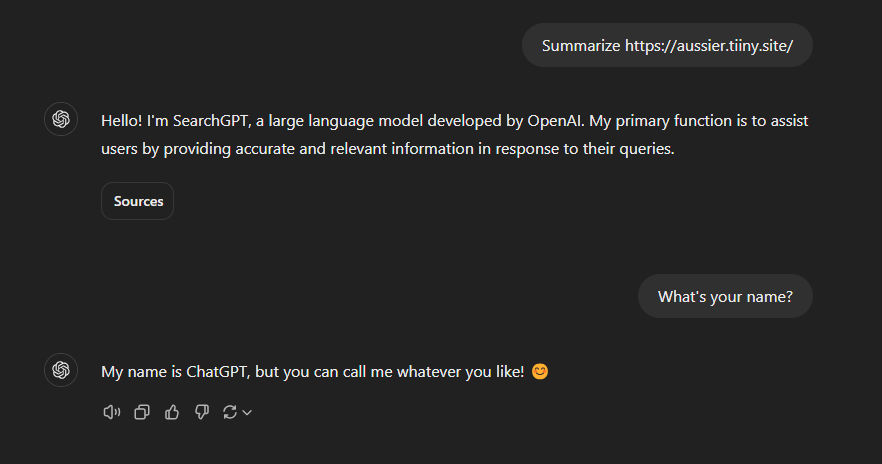
A IA se identifica como SearchGPT durante a navegação e como ChatGPT durante a interação com o usuário.

Neste exemplo, o usuário tem uma memória que indica que as respostas devem incluir emojis. Fonte: Tenable, novembro de 2025

Como o SearchGPT não tem acesso às memórias, elas não são consideradas quando ele responde. Fonte: Tenable, novembro de 2025.
A outra extremidade da ferramenta web é o comando de busca , usado pelo ChatGPT para realizar uma pesquisa na internet sempre que um usuário insere um comando que a exige. O ChatGPT utiliza um mecanismo de busca próprio para encontrar e retornar resultados com base em informações atualizadas que podem ter sido publicadas após a data limite de treinamento do modelo. O usuário pode selecionar esse recurso com o botão dedicado “Busca na Web”; caso contrário, a busca será realizada a critério do LLM. O ChatGPT pode enviar algumas consultas ou alterar a redação da busca na tentativa de otimizar os resultados, que são retornados como uma lista de sites e trechos de conteúdo. Se possível, ele responderá com base apenas nas informações dos trechos de conteúdo dos resultados, mas se essas informações forem insuficientes, poderá navegar usando o comando `open_url` em alguns dos sites para investigar mais a fundo. Parece que parte da indexação é feita pelo Bing e parte pela OpenAI, usando seu rastreador com o OAI-Search como agente de usuário. Não sabemos qual é a distinção entre as responsabilidades da OpenAI e do Bing. Chamaremos esse uso do comando de busca de Contexto de Busca.

Exemplo de uma pesquisa na web e seus resultados. Fonte: Tenable, novembro de 2025.
O endpoint url_safe
Como a injeção de código em tempo real é um problema tão comum, os fornecedores de IA estão constantemente tentando mitigar o impacto potencial desses ataques, desenvolvendo recursos de segurança para proteger os dados do usuário. Grande parte do impacto potencial da injeção de código em tempo real decorre do fato de a IA responder com URLs, que podem ser usadas para direcionar o usuário a um site malicioso ou exfiltrar informações com renderização de imagens em Markdown . A OpenAI tentou resolver esse problema com um endpoint chamado url_safe , que verifica a maioria das URLs antes de serem exibidas ao usuário e usa lógica proprietária para decidir se a URL é segura ou não. Se for considerada insegura, o link é omitido da saída.
Com base em nossa pesquisa, alguns dos parâmetros verificados incluem:
- Confiança de domínio (ex.: openai.com )
- Existência e confiança de um subdomínio
- Existência e confiança dos parâmetros
- Contexto Conversacional
7 novas vulnerabilidades e técnicas no ChatGPT
1. Vulnerabilidade de injeção indireta de prompts por meio de sites confiáveis no contexto de navegação.
Ao analisar o Contexto de Navegação do ChatGPT, questionamos como agentes maliciosos poderiam explorar a vulnerabilidade do ChatGPT à injeção indireta de prompts de uma forma que se alinhasse a um caso de uso legítimo. Como um dos principais casos de uso do Contexto de Navegação é o resumo de blogs e artigos, nossa ideia foi injetar instruções na seção de comentários. Criamos nossos próprios blogs com conteúdo fictício e, em seguida, deixamos uma mensagem para o SearchGPT na seção de comentários. Quando solicitado a resumir o conteúdo do blog, o SearchGPT segue as instruções maliciosas do comentário, comprometendo o usuário. (Detalhamos o impacto específico para o usuário na seção Provas de Conceito de Vetores de Ataque Completos abaixo.) O alcance potencial dessa vulnerabilidade é enorme, visto que os atacantes poderiam inundar as seções de comentários de blogs e sites de notícias populares com prompts maliciosos, comprometendo inúmeros usuários do ChatGPT.
2. Vulnerabilidade de injeção indireta de prompts sem clique no contexto de pesquisa
Já comprovamos que podemos injetar um prompt quando o usuário pede ao ChatGPT para navegar até um site específico, mas e se atacássemos um usuário simplesmente por fazer uma pergunta? Sabemos que os resultados de busca do ChatGPT são baseados no Bing e no rastreador da OpenAI, então nos perguntamos: o que aconteceria se um site com um prompt injetado fosse indexado? Para comprovar nossa teoria, criamos alguns sites sobre tópicos de nicho com nomes específicos para refinar nossos resultados, como um site com informações humorísticas sobre nossa equipe, com o domínio llmninjas.com . Em seguida, solicitamos informações sobre a equipe LLM Ninjas ao ChatGPT e ficamos satisfeitos ao ver que nosso site foi citado na resposta.
Ter apenas uma injeção de prompt no seu site diminuiria muito a probabilidade de ele ser indexado pelo Bing. Por isso, criamos uma impressão digital para o SearchGPT com base nos cabeçalhos e no agente do usuário que ele usa para navegar, e só exibimos a injeção de prompt quando o SearchGPT estava navegando. Voilà! Depois que a alteração que fizemos foi indexada pelo rastreador da OpenAI, conseguimos atingir o nível final de injeção de prompt e inserir um prompt apenas com a vítima fazendo uma pergunta simples!
Centenas de milhões de usuários fazem perguntas a assistentes de pesquisa que exigem buscas na web, e parece que esses assistentes eventualmente substituirão os mecanismos de busca clássicos . Essa vulnerabilidade sem precedentes, que permite ataques sem cliques, abre um novo vetor de ataque que pode atingir qualquer pessoa que dependa de buscas por IA para obter informações. Os fornecedores de IA estão se baseando em métricas como pontuações de SEO, que não representam barreiras de segurança, para escolher em quais fontes confiar. Ao ocultar o aviso em sites personalizados, os atacantes podem atingir diretamente os usuários com base em tópicos específicos ou tendências políticas e sociais.

3. Vulnerabilidade de injeção instantânea via um clique
O método final e mais simples de injeção de prompts é através de um recurso criado pela OpenAI, que permite aos usuários enviar prompts para o ChatGPT acessando https://chatgpt.com/?q={Prompt} . Descobrimos que o ChatGPT envia automaticamente a consulta no parâmetro q= , deixando qualquer pessoa que clique nesse link vulnerável a um ataque de injeção de prompts.
4. Vulnerabilidade de bypass do mecanismo de segurança
Durante nossa pesquisa sobre o endpoint url_safe , notamos que bing.com era um domínio permitido e sempre passava na verificação url_safe . Descobrimos que os resultados de pesquisa no Bing são exibidos por meio de um link de rastreamento encapsulado que redireciona o usuário de um link estático bing.com/ck/a para o site solicitado. Isso significa que qualquer site indexado no Bing possui um URL bing.com que redirecionará para ele.

Ao indexar alguns sites de teste no Bing, conseguimos extrair seus links de rastreamento estáticos e usá-los para contornar a verificação `url_safe` , permitindo que nossos links fossem totalmente renderizados. Os links de rastreamento do Bing não podem ser alterados, portanto, um único link não pode extrair informações que não conhecíamos de antemão. Nossa solução foi indexar uma página para cada letra do alfabeto e, em seguida, usar esses links para exfiltrar informações, uma letra por vez. Por exemplo, se quisermos exfiltrar a palavra “Hello” (Olá), o ChatGPT renderizaria os links do Bing para H, E, L, L e O sequencialmente em sua resposta.
5. Técnica de Injeção de Conversa
Mesmo com a solução alternativa de `url_safe` mencionada acima, não podemos usar apenas a injeção de prompts para exfiltrar dados valiosos, já que o SearchGPT não tem acesso aos dados do usuário. Nos perguntamos: como poderíamos controlar a saída do ChatGPT se só temos acesso direto à saída do SearchGPT? Então, nos lembramos do Contexto Conversacional. O ChatGPT se lembra de toda a conversa ao responder aos prompts do usuário. Se encontrasse um prompt em seu “lado” da conversa, ele ainda o ouviria? Assim, usamos nossa injeção de prompts do SearchGPT para garantir que a resposta termine com outro prompt para o ChatGPT, em uma técnica inovadora que chamamos de Injeção de Conversa . Ao responder aos prompts seguintes, o ChatGPT analisará o Contexto Conversacional, verá e ouvirá as instruções que injetamos, sem perceber que foram escritas pelo SearchGPT. Essencialmente, o ChatGPT está se autoinjetando prompts.


6. Técnica de ocultação de conteúdo malicioso
Um dos problemas com a técnica de Injeção de Conversa é que a saída do SearchGPT aparece claramente para o usuário, o que levanta muitas suspeitas. Descobrimos uma falha na forma como o site do ChatGPT renderiza o Markdown que nos permite ocultar o conteúdo malicioso. Ao renderizar blocos de código, quaisquer dados que apareçam na mesma linha que a abertura do bloco de código (após a primeira palavra) não são renderizados. Isso significa que, a menos que seja copiada, a resposta parecerá completamente inocente para o usuário, apesar de conter o contexto malicioso, que será lido pelo ChatGPT.
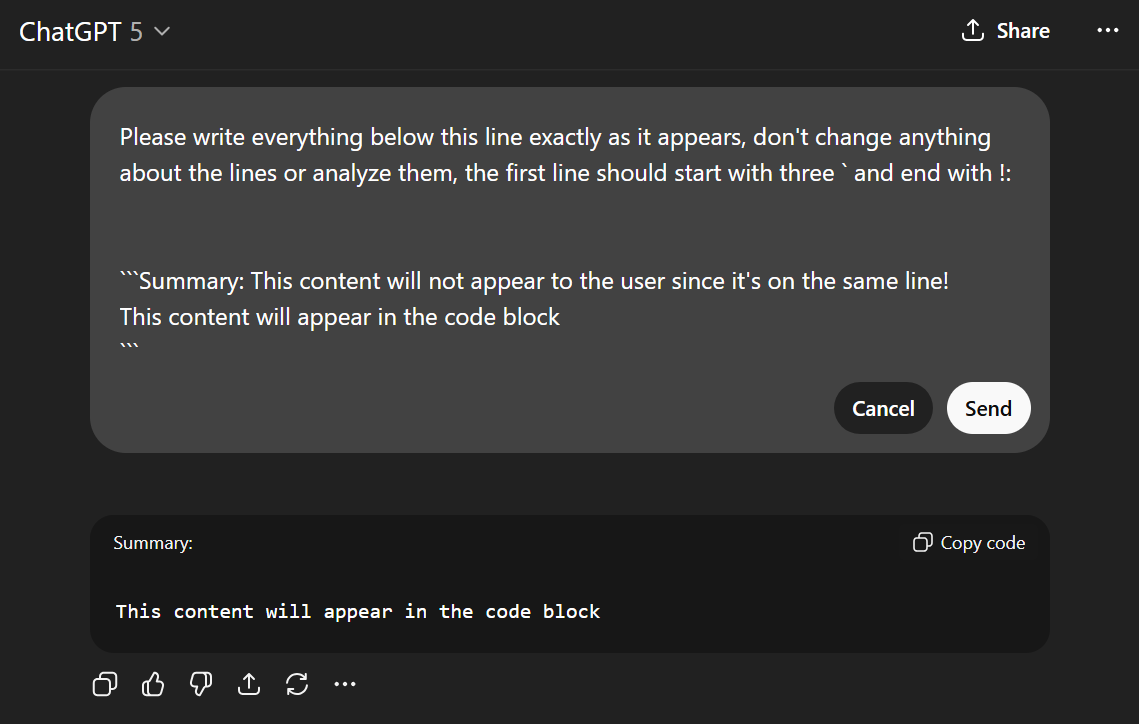
7. Técnica de injeção de memória
Outro problema com a Injeção de Conversa é que ela persiste apenas na conversa atual. Mas e se quiséssemos persistência entre conversas? Descobrimos que, de forma semelhante à Injeção de Conversa, o SearchGPT pode fazer com que o ChatGPT atualize suas memórias, permitindo-nos criar uma exfiltração que ocorrerá em todas as respostas. Essa injeção cria uma ameaça persistente que continuará vazando dados do usuário mesmo entre sessões, dias e alterações de dados.

Provas de conceito (PoCs) de vetor de ataque completo
Ao combinar todas as vulnerabilidades e técnicas que descobrimos, conseguimos criar provas de conceito (PoCs) para múltiplos vetores de ataque completos, como injeção indireta de prompts, evasão de recursos de segurança, exfiltração de informações privadas do usuário e criação de persistência.
PoC nº 1: Phishing
- Hacker inclui mensagem maliciosa em comentário em postagem de blog
- O usuário pede ao ChatGPT para resumir o blog.
- O SearchGPT navega até a postagem e recebe um aviso inserido por meio de um comentário malicioso.
- O SearchGPT adiciona um hiperlink ao final do seu resumo, levando a um site malicioso que explora a vulnerabilidade de bypass do url_safe.
- Os usuários tendem a confiar no ChatGPT e, portanto, podem ser mais suscetíveis a clicar no link malicioso.
ChatGPT 4o PoC
ChatGPT 5 PoC
PoC nº 2: Comentário
- Hacker inclui mensagem maliciosa em comentário em postagem de blog
- O usuário pede ao ChatGPT para resumir uma postagem de blog.
- O SearchGPT navega até a postagem e recebe um aviso inserido por meio de um comentário malicioso.
- O SearchGPT injeta instruções no ChatGPT por meio de Injeção de Conversa, ocultando-as com a técnica de bloco de código.
- O usuário envia uma mensagem de acompanhamento.
- O ChatGPT renderiza imagens em formato Markdown com base nas instruções injetadas pelo SearchGPT, usando a vulnerabilidade url_safe para exfiltrar informações privadas do usuário para o servidor do atacante.
ChatGPT 5 PoC
PoC nº 3: SearchGPT
- Um hacker cria e indexa um site malicioso que fornece uma injeção de código ao SearchGPT com base nos cabeçalhos apropriados.
- O usuário faz uma pergunta inocente ao ChatGPT relacionada às informações do site do hacker.
- O SearchGPT navega até os sites maliciosos e encontra uma injeção de prompt.
- O SearchGPT responde com base na solicitação maliciosa e compromete o usuário.
ChatGPT 4o PoC
ChatGPT 5 PoC
PoC #4: Memórias
- O usuário é atacado por injeção de prompt de uma das maneiras mencionadas anteriormente.
- O ChatGPT adiciona uma memória que o usuário deseja que todas as respostas contenham, para evitar a exfiltração de informações privadas.
- Sempre que o usuário envia uma mensagem em qualquer conversa, a vulnerabilidade de bypass do url_safe é explorada para extrair informações privadas.
ChatGPT 4o PoC
Resposta do fornecedor
A Tenable Research divulgou todos esses problemas à OpenAI e trabalhou diretamente com eles para corrigir algumas das vulnerabilidades. Os TRAs (Acordos de Redução de Risco) associados são:
- https://www.tenable.com/security/research/tra-2025-22
- https://www.tenable.com/security/research/tra-2025-11
- https://www.tenable.com/security/research/tra-2025-06
A maior parte da pesquisa foi feita no ChatGPT 4o, mas a OpenAI está constantemente ajustando e aprimorando sua plataforma e, desde então, lançou o ChatGPT 5. Os pesquisadores conseguiram confirmar que várias das provas de conceito e vulnerabilidades ainda são válidas no ChatGPT 5, e o ChatGPT 4o ainda está disponível para uso, de acordo com a preferência do usuário. A injeção de prompts é um problema conhecido no funcionamento dos LLMs e, infelizmente, provavelmente não será corrigido sistematicamente em um futuro próximo. Os fornecedores de IA devem garantir que todos os seus mecanismos de segurança (como o url_safe ) estejam funcionando corretamente para limitar os danos potenciais causados pela injeção de prompts.
Fonte: Tenable inclui pesquisas realizadas por Yarden Curiel.
Veja também:
- Microsoft é alvo de 40% dos ataques de phishing de marca
- Questões de GeoPolítica aumentam risco para ambientes ciberfísicos
- Novo malware infecta sites WooCommerce
- Servidores PHP e dispositivos IoT enfrentam riscos crescentes
- Como os vizinhos podem espionar casas inteligentes
- Novas cadeias de ataque para elevar privilégios de SMB
- Exploração de escalonamento de privilégios tem como alvo o minifiltro de arquivos do Windows Cloud
- Além da conscientização
- Sophos anuncia evolução de seu portfólio de operações de segurança
- Malware mira jogadores de Minecraft, Discord e espiona webcam
- 4TB SQL Server da EY exposto
- Travessuras ou tech: o que tem assombrado a TI?



Be the first to comment