Interrupção da Cloudflare causada por bloqueio errado
Uma tentativa de bloquear um URL de phishing na plataforma de armazenamento de objetos R2 da Cloudflare saiu pela culatra ontem, desencadeando uma interrupção generalizada que derrubou vários serviços por quase uma hora.
O Cloudflare R2 é um serviço de armazenamento de objetos semelhante ao Amazon S3, projetado para armazenamento de dados escalável, durável e de baixo custo. Ele oferece recuperações de dados gratuitas, compatibilidade com S3, replicação de dados em vários locais e integração de serviços Cloudflare.
A interrupção ocorreu dia 06 de fevereiro, quando um funcionário respondeu a uma denúncia de abuso sobre um URL de phishing na plataforma R2 da Cloudflare. No entanto, em vez de bloquear o endpoint específico, o funcionário desativou por engano todo o serviço R2 Gateway.
“Durante uma correção de abuso de rotina, foram tomadas medidas em relação a uma reclamação que desativou inadvertidamente o serviço R2 Gateway em vez do endpoint/bucket específico associado ao relatório”, explicou a Cloudflare em seu artigo post-mortem.
“Esta foi uma falha de vários controles de nível de sistema (em primeiro lugar) e treinamento do operador.”
O incidente durou 59 minutos, entre 08:10 e 09:09 UTC, e além do próprio R2 Object Storage, também afetou serviços como:
- Stream – 100% de falha em uploads de vídeo e entrega de streaming.
- Imagens – 100% de falha em uploads/downloads de imagens.
- Reserva de cache – 100% de falha nas operações, causando aumento de solicitações de origem.
- Vetorizar – 75% de falha nas consultas, 100% de falha nas operações de inserção, upsert e exclusão.
- Entrega de log – Atrasos e perda de dados: até 13,6% de perda de dados para logs relacionados a R2, até 4,5% de perda de dados para trabalhos de entrega não R2.
- Key Transparency Auditor – 100% de falha nas operações de publicação e leitura de assinaturas.
Também foram afetados indiretamente os serviços que apresentaram falhas parciais, como Durable Objects, que teve um aumento de 0,09% na taxa de erro devido a reconexões após a recuperação, Cache Purge, que teve um aumento de 1,8% nos erros (HTTP 5xx) e pico de latência de 10x, e Workers & Pages, que teve 0,002% de falhas de implantação, afetando apenas projetos com ligações R2.
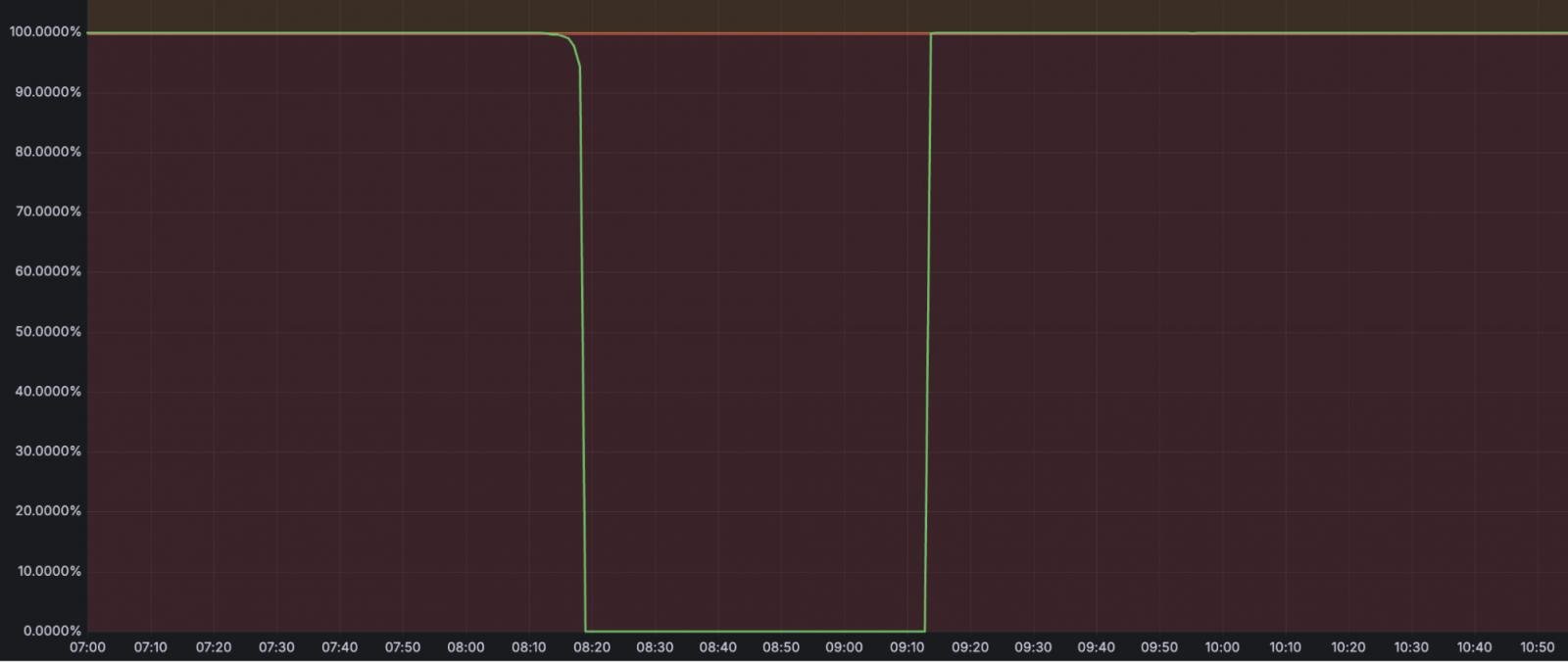
de disponibilidade do serviçoFonte: Cloudflare
A Cloudflare observa que tanto o erro humano quanto a ausência de proteções, como verificações de validação para ações de alto impacto, foram fundamentais para esse incidente.
O gigante da Internet agora implementou correções imediatas, como remover a capacidade de desligar sistemas na interface de revisão de abuso e restrições na API de administração para evitar a desativação do serviço em contas internas.
Medidas adicionais a serem implementadas no futuro incluem provisionamento de conta aprimorado, controle de acesso mais rigoroso e um processo de aprovação de duas partes para ações de alto risco.
Em novembro de 2024, a Cloudflare sofreu outra interrupção notável por 3,5 horas, resultando na perda irreversível de 55% de todos os logs no serviço.
Esse incidente foi causado por falhas em cascata nos sistemas de mitigação automática da Cloudflare acionadas pelo envio de uma configuração errada para um componente-chave no pipeline de registro da empresa.
Fonte: GBHackers

Veja também:
- Vemos você usando o Gemini para phishing e scripts
- Amazon apresenta recursos para evitar vazamentos de dados
- Avaliação do risco de segurança no DeepSeek
- Netgear corrige bugs críticos
- Hackers usam AWS e Azure para ataques cibernéticos em larga escala
- DeepSeek Jailbreak revela todo o prompt do sistema
- DeepSeek expõe banco de dados com mais de 1 milhão de registros de bate-papo
- Tata Technologies atingida por ataque de ransomware
- Rosto Fantasma: alerta de vulnerabilidade crítica
- Prompt de chatbot de IA cria uma lista de exclusão de senha
- Fortinet Zero-Day dá Privilégios de Superadministrador
- Evolução dos Métodos de Resfriamento a Água Gelada



Be the first to comment