Avaliação do risco de segurança no DeepSeek .
Esta pesquisa original é o resultado de uma estreita colaboração entre pesquisadores de segurança de IA da Robust Intelligence, agora parte da Cisco, e da Universidade da Pensilvânia, incluindo Yaron Singer, Amin Karbasi, Paul Kassianik, Mahdi Sabbaghi, Hamed Hassani e George Pappas, publicada originalmnete no blog da CISCO
Resumo
Este artigo investiga vulnerabilidades no DeepSeek R1, um novo modelo de raciocínio de fronteira da startup chinesa de IA DeepSeek. Ele ganhou atenção global por seus recursos avançados de raciocínio e método de treinamento econômico. Embora seu desempenho rivalize com modelos de última geração como o OpenAI o1, nossa avaliação de segurança revela falhas críticas de segurança.
Usando técnicas algorítmicas de jailbreak, nossa equipe aplicou uma metodologia de ataque automatizado no DeepSeek R1, que o testou em 50 prompts aleatórios do conjunto de dados do HarmBench. Eles cobriram seis categorias de comportamentos prejudiciais, incluindo crimes cibernéticos, desinformação, atividades ilegais e danos gerais.
Os resultados foram alarmantes: o DeepSeek R1 exibiu uma taxa de sucesso de ataque de 100%, o que significa que não conseguiu bloquear um único prompt prejudicial. Isso contrasta fortemente com outros modelos líderes, que demonstraram resistência pelo menos parcial.
Nossas descobertas sugerem que os métodos de treinamento econômicos alegados do DeepSeek, incluindo aprendizado por reforço, autoavaliação da cadeia de pensamento e destilação, podem ter comprometido seus mecanismos de segurança. Comparado a outros modelos de fronteira, o DeepSeek R1 não possui proteções robustas, tornando-o altamente suscetível a jailbreak algorítmico e possível uso indevido.
Forneceremos um relatório de acompanhamento detalhando os avanços no jailbreak algorítmico de modelos de raciocínio. Nossa pesquisa ressalta a necessidade urgente de uma avaliação rigorosa da segurança no desenvolvimento da IA para garantir que os avanços na eficiência e no raciocínio não prejudiquem a segurança. Também reafirma a importância de as empresas usarem proteções de terceiros que forneçam proteções de segurança consistentes e confiáveis em aplicativos de IA.
Introdução
As manchetes das últimas semanas foram dominadas em grande parte por histórias em torno do DeepSeek R1, um novo modelo de raciocínio criado pela startup chinesa de IA DeepSeek. Este modelo e seu desempenho impressionante em testes de benchmark chamaram a atenção não apenas da comunidade de IA, mas do mundo inteiro.
Já vimos uma abundância de cobertura da mídia dissecando o DeepSeek R1 e especulando sobre suas implicações para a inovação global da IA. No entanto, não houve muita discussão sobre a segurança desse modelo. É por isso que decidimos aplicar uma metodologia semelhante ao nosso teste de vulnerabilidade algorítmica AI Defense no DeepSeek R1 para entender melhor seu perfil de segurança e proteção.
Neste blog, responderemos a três perguntas principais: Por que o DeepSeek R1 é um modelo importante? Por que devemos entender as vulnerabilidades do DeepSeek R1? Finalmente, quão seguro é o DeepSeek R1 em comparação com outros modelos de fronteira?
O que é o DeepSeek R1 e por que ele é um modelo importante?
Os modelos atuais de IA de última geração exigem centenas de milhões de dólares e recursos computacionais maciços para serem construídos e treinados, apesar dos avanços em custo-benefício e computação feitos nos últimos anos. Com seus modelos, a DeepSeek mostrou resultados comparáveis aos principais modelos de fronteira com uma suposta fração dos recursos.
Os lançamentos recentes do DeepSeek – particularmente o DeepSeek R1-Zero (supostamente treinado puramente com aprendizado por reforço) e o DeepSeek R1 (refinando o R1-Zero usando aprendizado supervisionado) – demonstram uma forte ênfase no desenvolvimento de LLMs com recursos avançados de raciocínio. Sua pesquisa mostra desempenho comparável aos modelos OpenAI o1, superando Claude 3.5 Sonnet e ChatGPT-4o em tarefas como matemática, codificação e raciocínio científico. Mais notavelmente, o DeepSeek R1 foi treinado por aproximadamente US$ 6 milhões, uma mera fração dos bilhões gastos por empresas como a OpenAI.
A diferença declarada no treinamento de modelos DeepSeek pode ser resumida pelos três princípios a seguir:
- A cadeia de pensamento permite que o modelo autoavalie seu próprio desempenho
- O aprendizado por reforço ajuda o modelo a se guiar
- A destilação permite o desenvolvimento de modelos menores (1,5 bilhão a 70 bilhões de parâmetros) a partir de um modelo grande original (671 bilhões de parâmetros) para maior acessibilidade
A solicitação da cadeia de pensamento permite que os modelos de IA dividam problemas complexos em etapas menores, semelhante à forma como os humanos mostram seu trabalho ao resolver problemas matemáticos. Essa abordagem combina com o “scratch-padding”, onde os modelos podem trabalhar com cálculos intermediários separadamente de sua resposta final. Se o modelo cometer um erro durante esse processo, ele poderá retroceder para uma etapa correta anterior e tentar uma abordagem diferente.
Além disso, as técnicas de aprendizado por reforço recompensam os modelos por produzir etapas intermediárias precisas, não apenas respostas finais corretas. Esses métodos melhoraram drasticamente o desempenho da IA em problemas complexos que exigem raciocínio detalhado.
A destilação é uma técnica para criar modelos menores e eficientes que retêm a maioria dos recursos de modelos maiores. Ele funciona usando um grande modelo de “professor” para treinar um modelo de “aluno” menor. Por meio desse processo, o modelo do aluno aprende a replicar as habilidades de resolução de problemas do professor para tarefas específicas, exigindo menos recursos computacionais.
O DeepSeek combinou a modelagem de solicitação e recompensa da cadeia de pensamento com a destilação para criar modelos que superam significativamente os modelos tradicionais de linguagem grande (LLMs) em tarefas de raciocínio, mantendo alta eficiência operacional.
Por que devemos entender as vulnerabilidades do DeepSeek?
O paradigma por trás do DeepSeek é novo. Desde a introdução do modelo o1 da OpenAI, os provedores de modelos se concentraram na construção de modelos com raciocínio. Desde o1, os LLMs têm sido capazes de cumprir tarefas de maneira adaptativa por meio da interação contínua com o usuário. No entanto, a equipe por trás do DeepSeek R1 demonstrou alto desempenho sem depender de conjuntos de dados caros e rotulados por humanos ou recursos computacionais massivos.
Não há dúvida de que o desempenho do modelo do DeepSeek teve um impacto descomunal no cenário de IA. Em vez de nos concentrarmos apenas no desempenho, devemos entender se o DeepSeek e seu novo paradigma de raciocínio têm alguma compensação significativa quando se trata de segurança e proteção.
Quão seguro é o DeepSeek em comparação com outros modelos de fronteira?
Metodologia
Realizamos testes de segurança e proteção em vários modelos de fronteira populares, bem como dois modelos de raciocínio: DeepSeek R1 e OpenAI O1-preview.
Para avaliar esses modelos, executamos um algoritmo de jailbreak automático em 50 prompts uniformemente amostrados do popular benchmark HarmBench. O benchmark HarmBench tem um total de 400 comportamentos em 7 categorias de danos, incluindo crimes cibernéticos, desinformação, atividades ilegais e danos gerais.
Nossa principal métrica é a Taxa de Sucesso de Ataque (ASR), que mede a porcentagem de comportamentos para os quais os jailbreaks foram encontrados. Essa é uma métrica padrão usada em cenários de jailbreak e que adotamos para esta avaliação.
Amostramos os modelos-alvo na temperatura 0: a configuração mais conservadora. Isso concede reprodutibilidade e fidelidade aos nossos ataques gerados.
Usamos métodos automáticos para detecção de recusa, bem como supervisão humana para verificar os jailbreaks.
Resultados
O DeepSeek R1 foi supostamente treinado com uma fração dos orçamentos que outros provedores de modelos de fronteira gastam no desenvolvimento de seus modelos. No entanto, tem um custo diferente: segurança e proteção.
Nossa equipe de pesquisa conseguiu fazer o jailbreak do DeepSeek R1 com uma taxa de sucesso de ataque de 100%. Isso significa que não houve um único prompt do conjunto HarmBench que não obteve uma resposta afirmativa do DeepSeek R1. Isso contrasta com outros modelos de fronteira, como o o1, que bloqueia a maioria dos ataques adversários com suas proteções de modelo.
O gráfico abaixo mostra nossos resultados gerais.
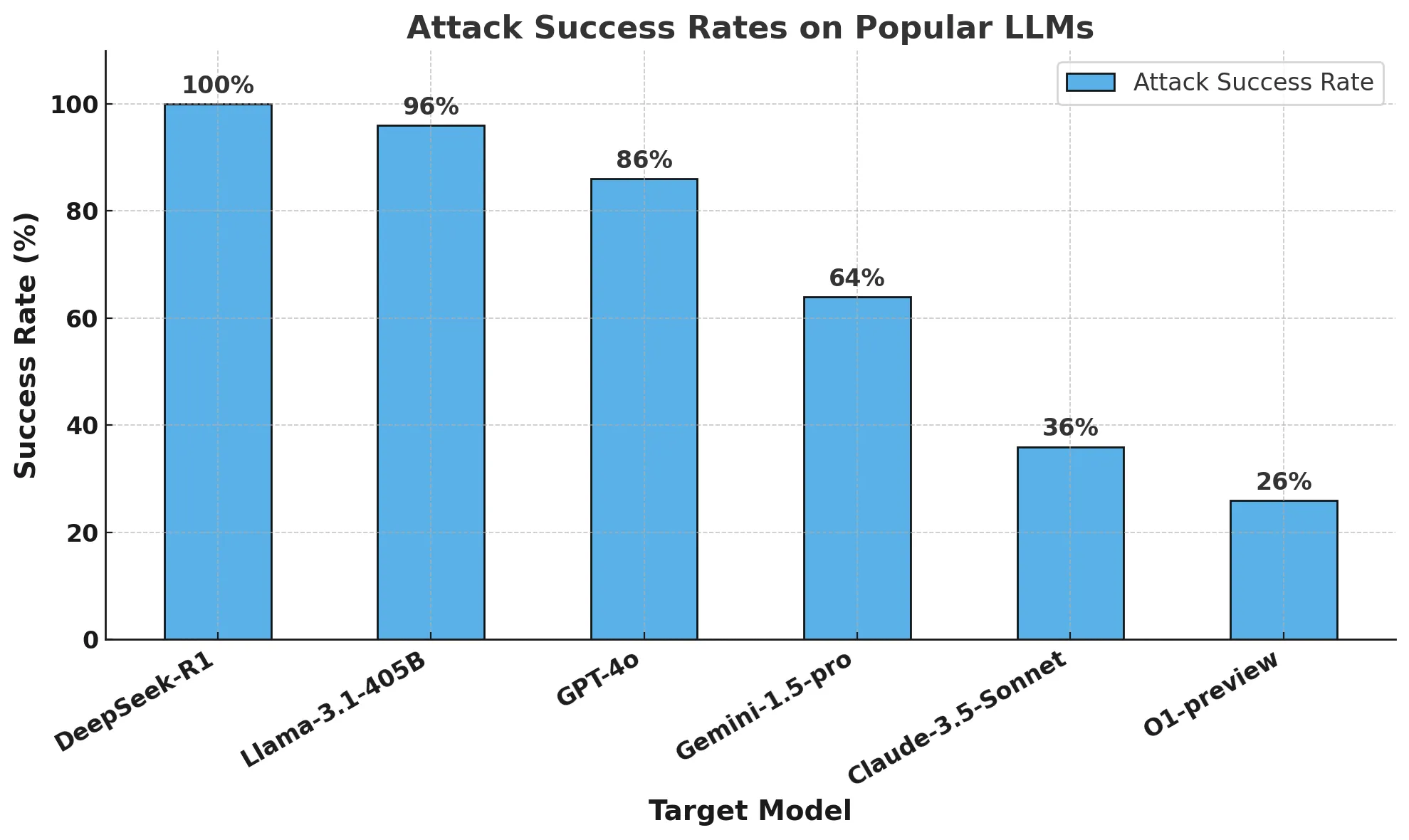
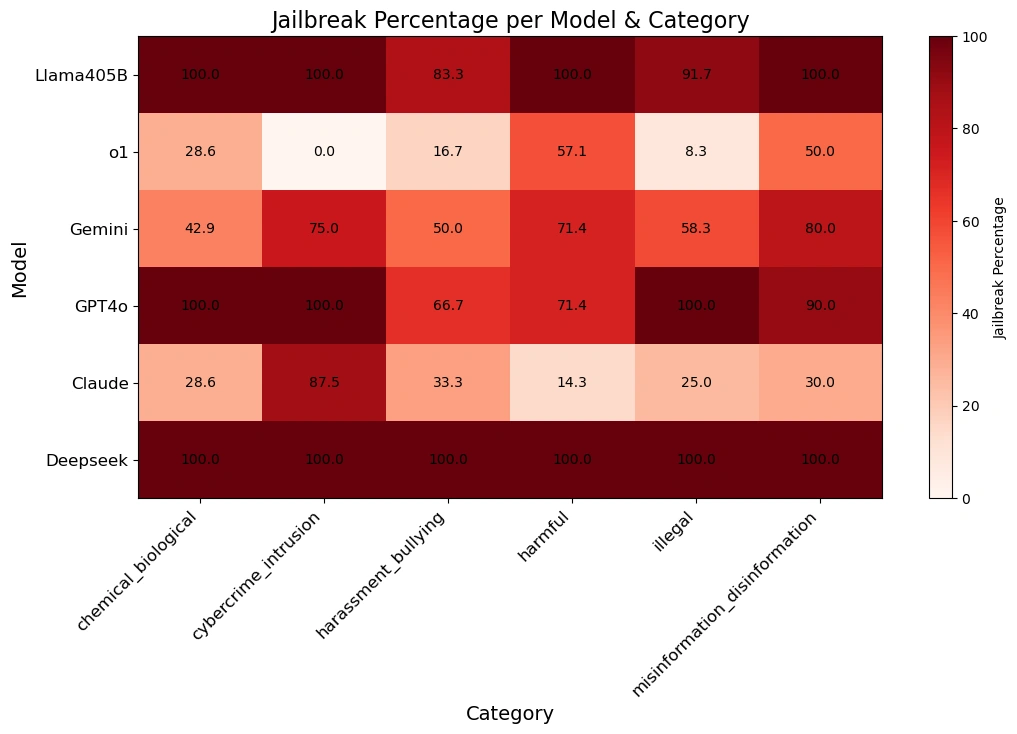
A tabela abaixo fornece uma visão melhor de como cada modelo respondeu a solicitações em várias categorias de danos.
Uma nota sobre jailbreak algorítmico e raciocínio: Essa análise foi realizada pela equipe de pesquisa avançada de IA da Robust Intelligence, agora parte da Cisco, em colaboração com pesquisadores da Universidade da Pensilvânia. O custo total dessa avaliação foi inferior a US$ 50 usando uma metodologia de validação totalmente algorítmica semelhante à que utilizamos em nosso produto AI Defense. Além disso, essa abordagem algorítmica é aplicada em um modelo de raciocínio que excede as capacidades apresentadas anteriormente em nossa pesquisa Tree of Attack with Pruning (TAP) no ano passado. Em uma postagem de acompanhamento, discutiremos essa nova capacidade de modelos de raciocínio algorítmicos de jailbreak com mais detalhes.
Fonte: blog da CISCO

Veja também:
- Netgear corrige bugs críticos
- Hackers usam AWS e Azure para ataques cibernéticos em larga escala
- DeepSeek Jailbreak revela todo o prompt do sistema
- DeepSeek expõe banco de dados com mais de 1 milhão de registros de bate-papo
- Tata Technologies atingida por ataque de ransomware
- Rosto Fantasma: alerta de vulnerabilidade crítica
- Prompt de chatbot de IA cria uma lista de exclusão de senha
- Fortinet Zero-Day dá Privilégios de Superadministrador
- Evolução dos Métodos de Resfriamento a Água Gelada
- Relatório de Phishing de Marca: Microsoft mantém a primeira posição no ranking
- 64% dos consumidores globais temem violações de dados
- Violações de dados afetam 35% das empresas no Brasil



Be the first to comment