Você sabe o que é um Data Lake ? Um data lake é um repositório de armazenamento que mantém uma grande quantidade de dados brutos (raw data) em seu formato nativo enquanto for necessário.
Enquanto um data warehouse hierárquico armazena dados em arquivos ou pastas, um data lake usa uma arquitetura simples para armazenar dados . Cada elemento de dados em um lake recebe um identificador exclusivo e é marcado com um conjunto de tags de metadados estendidas. Quando surge uma pergunta comercial, o data lake pode ser consultado em busca de dados relevantes e esse conjunto menor de dados pode ser analisado para ajudar a responder à pergunta.
Segundo o site TechTarget, o termo data lake é frequentemente associado ao armazenamento de objetos orientados ao Hadoop . Nesse cenário, os dados de uma organização são carregados primeiro na plataforma Hadoop e, em seguida, ferramentas de análise de negócios e de mineração de dados são aplicadas aos dados em que residem nos nós de cluster dos computadores comuns do Hadoop.
“O termo descreve uma estratégia de armazenamento de dados, não uma tecnologia específica”
Como big data, o termo data lake às vezes é menosprezado por ser simplesmente um rótulo de marketing para um produto que suporta o Hadoop. Cada vez mais, no entanto, o termo está sendo usado para descrever qualquer grande conjunto de dados no qual o esquema e os requisitos de dados não sejam definidos até que os dados sejam consultados.
O termo descreve uma estratégia de armazenamento de dados, não uma tecnologia específica, embora seja frequentemente usada em conjunto com uma tecnologia específica (Hadoop). O mesmo pode ser dito do termo data warehouse , que apesar de frequentemente se referir a uma tecnologia específica (banco de dados relacional), na verdade descreve uma ampla estratégia de gerenciamento de dados.
Data lake vs. Data Warehouse
Data Lake e Data Warehouses são duas estratégias diferentes para armazenar big data. A distinção mais importante entre eles é que, em um data warehouse, o esquema para os dados é predefinido; isto é, existe um plano para os dados após sua entrada no banco de dados. Em um data lake, esse não é necessariamente o caso. Um data lake pode abrigar dados estruturados e não estruturados e não possui um esquema predeterminado. Um data warehouse lida principalmente com dados estruturados e possui um esquema predeterminado para os dados que hospeda.
Para simplificar, pense no conceito de armazém versus o conceito de lago. Um lago é líquido, instável, amorfo, praticamente não estruturado e é alimentado por rios, córregos e outras fontes não filtradas de água. Um armazém, por outro lado, é uma estrutura feita pelo homem, com prateleiras e corredores e locais designados para as coisas dentro dele. Os armazéns armazenam mercadorias selecionadas de fontes específicas. Os armazéns são pré-estruturados, os lagos não.
Essa principal diferença conceitual se manifesta de várias maneiras, incluindo:
Tecnologia normalmente usada para hospedar dados – Um data warehouse geralmente é um banco de dados relacional alojado em um servidor mainframe corporativo ou na nuvem, enquanto um data lake geralmente é alojado em um ambiente Hadoop ou em um repositório de big data semelhante.
Origem dos dados – Os dados armazenados em um data warehouse são extraídos de vários aplicativos de processamento de transações online para dar suporte a consultas de análise de negócios e data marts para grupos de negócios internos específicos, como equipes de vendas ou inventário. Os data lakes geralmente recebem dados relacionais e não relacionais de dispositivos IoT, mídia social, aplicativos móveis e aplicativos corporativos.
Usuários – Os data warehouses são úteis quando há uma enorme quantidade de dados de sistemas operacionais que precisam estar prontamente disponíveis para análise. Os data lakes são mais úteis quando uma organização precisa de um grande repositório de dados, mas não tem um objetivo para todos eles e pode se dar ao luxo de aplicar um esquema a ele após o acesso.
Como os dados em um lake geralmente não são curados e podem se originar de fontes externas aos sistemas operacionais da empresa, os lakes não são adequados para o usuário médio de análise de negócios. Em vez disso, os data lakes são mais adequados para uso dos cientistas de dados, porque é necessário um nível de habilidade para classificar o grande corpo de dados não curados e extrair prontamente o significado deles.
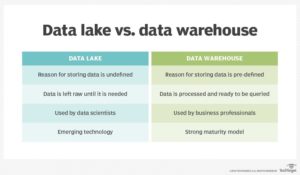
Qualidade dos dados – Em um data warehouse, os dados altamente selecionados são geralmente confiáveis como a versão central porque já contêm dados processados. Os dados em um data lake são menos confiáveis porque podem estar chegando de qualquer fonte em qualquer estado. Pode ser com curadoria, e pode não ser, dependendo da fonte.
Processamento – O esquema para data warehouses está em gravação, o que significa que é pré-definido para quando os dados são inseridos no armazém. O esquema para um data lake é lido, o que significa que ele não existe até que os dados sejam acessados e alguém escolhe usá-lo para alguma coisa.
Desempenho / custo – os data warehouses geralmente são mais caros para grandes volumes de dados, mas o trade-off é resultados de consultas mais rápidos, confiabilidade e desempenho superior. Os data lakes são projetados com baixo custo em mente, mas os resultados das consultas estão melhorando à medida que o conceito e as tecnologias vizinhas amadurecem.
Agilidade – os data lakes são altamente ágeis ; eles podem ser configurados e reconfigurados conforme necessário. Os data warehouses são menos.
Segurança – os data warehouses geralmente são mais seguros do que os data lake porque os warehouses como conceito existem há mais tempo e, portanto, os métodos de segurança tiveram a oportunidade de amadurecer.
Arquitetura do Data Lake
A arquitetura física de um data lake pode variar, pois o data lake é uma estratégia que pode ser aplicada a várias tecnologias. Por exemplo, a arquitetura física de um data lake usando o Hadoop pode ser diferente da arquitetura do data lake usando o Amazon Simple Storage Service ( Amazon S3 ).
No entanto, existem três princípios principais que distinguem um data lake de outros métodos de armazenamento de big data e compõem a arquitetura básica de um data lake. Eles são:
- Nenhum dado é recusado. Todos os dados são carregados de vários sistemas de origem e retidos.
- Os dados são armazenados em um estado não transformado ou quase não transformado, conforme foram recebidos da fonte.
- Os dados são transformados e ajustados em um esquema com base nos requisitos de análise.
Embora os dados sejam amplamente não estruturados e não voltados para responder a uma pergunta específica, eles ainda devem ser organizados de alguma maneira, para que isso seja possível no futuro. Qualquer que seja a tecnologia que acabe sendo usada para implantar o data lake de uma organização, alguns recursos devem ser incluídos para garantir que o data lake seja funcional e íntegro e que o grande repositório de dados não estruturados não seja desperdiçado. Esses incluem:
- Uma taxonomia de classificações de dados, que pode incluir tipo de dados, conteúdo, cenários de uso e grupos de possíveis usuários.
- Uma hierarquia de arquivos com convenções de nomenclatura.
- Ferramentas de criação de perfil de dados para fornecer informações para classificar objetos de dados e solucionar problemas de qualidade de dados.
- Processo padronizado de acesso a dados para acompanhar quais membros de uma organização estão acessando dados.
- Um catálogo de dados pesquisável.
- Proteções de dados, incluindo mascaramento de dados, criptografia de dados e monitoramento automatizado para gerar alertas quando os dados são acessados por terceiros não autorizados.
- Consciência de dados entre os funcionários, que inclui um entendimento do gerenciamento e governança de dados adequados , treinamento sobre como navegar no data lake e um entendimento da forte qualidade dos dados e do uso adequado dos dados.
Benefícios de um data lake
O data lake oferece vários benefícios, incluindo:
- A capacidade de desenvolvedores e cientistas de dados configurarem facilmente um determinado modelo, aplicativo ou consulta de dados em tempo real. O data lake é altamente ágil.
- Os data lake são teoricamente mais acessíveis. Como não há estrutura inerente, qualquer usuário pode acessar tecnicamente os dados no data lake, mesmo que a prevalência de grandes quantidades de dados não estruturados possa inibir usuários menos qualificados.
- O data lake suporta usuários de diferentes níveis de investimento; usuários que desejam retornar à fonte para recuperar mais informações, aqueles que procuram responder a perguntas totalmente novas com os dados e aqueles que simplesmente exigem um relatório diário. O acesso é possível para cada um desses tipos de usuários.
- Implementar Data Lakes é barato, porque a maioria das tecnologias usadas para gerenciá-los é de código aberto (ou seja, Hadoop) e pode ser instalada em hardware de baixo custo.
- O desenvolvimento é trabalhoso e a limpeza de dados são adiados até que a organização identifique uma necessidade de negócio claro para os dados.
- A agilidade permite uma variedade de métodos analíticos diferentes para interpretar dados, incluindo análise de big data, análise em tempo real, aprendizado de máquina e consultas SQL.
- Escalável por falta de estrutura.
Crítica
Apesar dos benefícios de ter um repositório de dados barato e não estruturado à disposição de uma organização, várias críticas legítimas foram feitas contra a estratégia.
Uma das maiores loucuras em potencial do data lake é que ele pode se transformar em um pântano de dados ou cemitério de dados. Se uma organização pratica má governança e gerenciamento de dados, pode perder o controle dos dados que existem no lake, mesmo com a chegada de mais. O resultado é um corpo desperdiçado de dados potencialmente valiosos que desaparecem sem serem vistos na “parte inferior” dos dados, por assim dizer, tornando-o deteriorado, incontrolável e inacessível.
Os Data Lakes, embora ofereçam acessibilidade teórica a qualquer pessoa em uma organização, podem não ser tão acessíveis no uso prático, porque os analistas de negócios podem ter dificuldade em analisar prontamente dados não estruturados de várias fontes. Esse desafio prático da acessibilidade também pode contribuir para a falta de manutenção adequada dos dados e resultar no desenvolvimento de um cemitério de dados. É importante maximizar o investimento em um data lake e reduzir o risco de falha na implantação.
Outro problema com o termo data lake em si é que ele é usado em muitos contextos no discurso público. Embora faça mais sentido usá-lo para descrever uma estratégia de gerenciamento de dados, ele também costuma ser usado para descrever tecnologias específicas e, como resultado, possui um nível de arbitrariedade. Esse desafio pode deixar de existir quando o termo amadurecer e encontrar um significado mais concreto no discurso público.
Fornecedores
Embora um data lake não seja uma tecnologia específica, existem várias tecnologias que as habilitam. Alguns fornecedores que oferecem essas tecnologias são:
- Apache – oferece o ecossistema de código aberto Hadoop, um dos serviços mais comuns do data lake.
- Amazon – oferece Amazon S3 com escalabilidade praticamente ilimitada.
- Google – oferece o Google Cloud Storage e uma coleção de serviços para emparelhá-lo no gerenciamento.
- Oracle – oferece o Oracle Big Data Cloud e uma variedade de serviços PaaS para ajudar a gerenciá-lo.
- Microsoft – oferece o Azure Data Lake como um armazenamento de dados escalável e o Azure Data Lake Analytics como um serviço de análise paralela. Este é um exemplo de quando o termo data lake é usado para se referir a uma tecnologia específica em vez de uma estratégia.
- HVR – oferece uma solução escalável para organizações que precisam mover grandes volumes de dados e atualizá-los em tempo real.
- Podium – oferece uma solução com um conjunto fácil de implementar e usar de recursos de gerenciamento.
- Snowflake – oferece uma solução especializada no processamento de diversos conjuntos de dados, incluindo conjuntos de dados estruturados e semiestruturados, como JSON, XML e Parquet.
- Zaloni – oferece uma solução que acompanha o Mica, uma ferramenta de preparação de dados de autoatendimento e catálogo de dados. Zaloni foi marcado como a empresa do data lake.
Fonte: Tech Target by Margaret Rouse
Veja também:
- O que Computação Confidencial ? Confidential Computing Consortium
- Anonymous ameaça expor ‘crimes’ da polícia dos EUA e cita Jair Bolsonaro
- Adversários do eCrime ajustam as técnicas de engenharia social
- Trabalhar em casa por um tempo? Veja como fazê-lo com segurança.
- Mulheres são melhores em segurança cibernética do que homens
- Ataques RangeAmp podem derrubar sites e servidores CDN
- Segundo Patch da Microsoft para RDP que não funciona corretamente
- Senado aprova PL sobre Direito Privado na pandemia
- 10 controles que podem estar faltando em sua arquitetura de nuvem
- CISA e FBI publicam vulnerabilidades mais exploradas desde 2016
- Prioridades e Orçamento do CISO durante a resposta ao COVID-19
- Cibercriminosos exploram o trabalho remoto atacando portas RDP


Deixe sua opinião!